
13. Markov Decision Process
-
Contents
-
Markov Process
-
Markov Reward Process
-
Markov Decision Process
-
Bellman Equations
-
-
Summary
-
Let’s find a trajectory (a sequence of states and actions) that maximizes the reward in a given MDP.
-
It’s complex to find the argmax of long-term value functions directly.
-
The Bellman equations allow us to break down complex, long-term value functions into recursive steps.
-
This enables us to find a reward-maximizing trajectory in an iterative manner.
-
13.1 Markov Process
-
Markov process is a type of stochastic (random) process that satisfies the Markov property.
- Markov Property : The future state depends only on the current state, not on the sequence of events that preceded it.
-
Key Features:
-
Memoryless: The process has no “memory” of past states.
-
State transitions: It moves from one state to another based on certain probabilities.
-
State space: The set of all possible states.
-
Transition probability: The chance of moving from one state to another.
-
-
Ex) Let’s say the weather can be Sunny or Rainy. A Markov process might define the following:
-
If it’s Sunny today, there’s an 80% chance it’ll be Sunny tomorrow and 20% chance of Rain.
-
If it’s Rainy today, there’s a 50% chance it’ll be Sunny tomorrow and 50% chance of Rain.
-
This process doesn’t care how long it’s been Sunny or Rainy—just what the current state is.
-
-
Markov Chain : A Markov process with discrete time steps and a finite (or countable) state space.
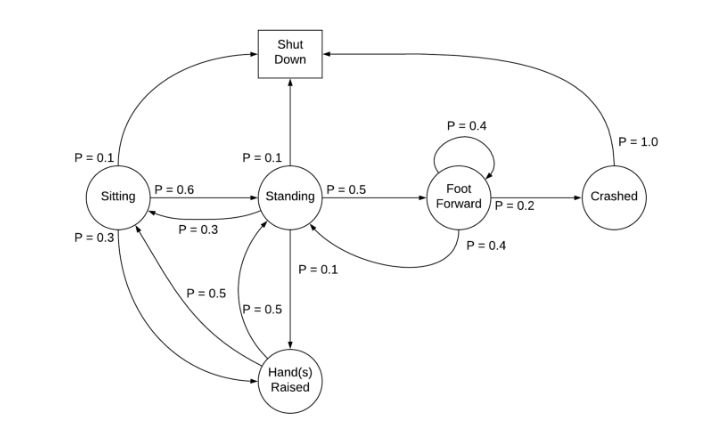
Markov Process Example
13.2 Markov Reward Process
-
Markov Reward Process (MRP) is a Markov process with rewards added. It’s a mathematical framework used to model situations where outcomes are partly random and partly under the control of a reward structure.
-
Components
-
States (S) – A finite set of possible situations.
-
Transition probabilities (P) – The probability of moving from one state to another.
-
Reward function (R) – The expected immediate reward received after entering a state.
-
Discount factor (γ) – A number between 0 and 1 that represents how much future rewards are worth compared to immediate rewards.
-
-
Return $G_t$ : the total (summation of) discounted reward from time-step $t$
$$ G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} \dots = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} $$
-
Value Function : tells us the expected total future reward from each state.
-
represent value of each state
-
This equation tells us the value of being in a state s as the immediate reward $R(s)$ plus the expected value of future states.
-
$$ V(s) = R(s) + \gamma \sum_{s{\prime}} P(s{\prime}|s) V(s{\prime}) $$
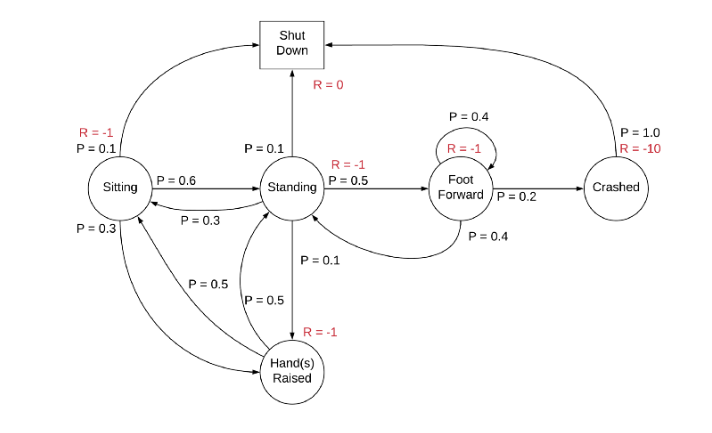
Markov Reward Process Example
13.3 Markov Decision Process
-
Markov Decision Process : is a MRP with action added. A framework used to describe an agent that makes sequential decisions in a stochastic (random) environment, where the goal is to maximize cumulative rewards over time.
-
Components
-
States (S): What situation the agent is currently in
-
Actions (A): What choices the agent can make
-
Transitions (P): What the world does in response (random but governed by probabilities)
-
Rewards (R): What the agent gets (positive or negative feedback)
-
Policy (π): A strategy that maps states to actions
-
Discount Factor (γ): A way to value the future compared to now
-
-
State Value Function : the expected return starting from states $s$, and then following the policy
$$ V_\pi(s) = \mathbb{E}_\pi \left[ G_t \mid S_t = s\right] $$
-
Action Value Function : the expected return (total future reward) starting from state s, taking action a, and then following policy $\pi$ thereafter.
- tells you how good it is to take a specific action in a specific state, assuming you act according to some policy afterward.
$$ Q^\pi(s, a) = \mathbb{E}_\pi \left[ G_t \mid S_t = s, A_t = a \right] $$
Bellman Equation
-
Value Functions (from above)
-
While the state-value function $V^\pi(s)$ gives the value of just being in a state,
-
the action-value function $Q^\pi(s, a)$ evaluates the value of a specific decision.
-
-
Bellman Equation : is a recursive formula that decomposes the value function into two components
-
The immediate reword $R_{t+1}$
-
Discounted value of the future state $γ.v(S_{t+1})$
-
-
Bellman Equation for the State-Value Function $V^\pi(s)$
- The value of state $s$ under policy $\pi$ is the expected reward for taking an action a in that state, plus the discounted value of the next state $s{\prime}$, assuming you follow policy $\pi$ thereafter.
$$ V_\pi(s) = E[R_{t+1} + \gamma V_\pi(S_{t+1}) | S_t = s] $$
-
Bellman Equation for the Action-Value Function $Q^\pi(s, a)$
- The value of taking action a in state $s$ is the immediate reward plus the discounted expected value of the actions in the next state, again following policy $\pi$.
$$ Q^\pi(s, a) = R(s, a) + \gamma \sum_{s^{\prime}} P(s^{\prime}|s, a) \sum_{a^{\prime}} \pi(a^{\prime}|s^{\prime}) Q^\pi(s^{\prime}, a^{\prime}) $$
-
Why Bellman Equations Matter:
-
Bellman Equations allow us to break down complex, long-term value calculations into recursive steps.
-
Make it possible to use many iterative RL algorithms
-