
Summary
- Overview : Techniques that improve the performance of large language models
- RAG (Retrieval Augmented Generation)
- Improved factual accuracy: The model can refer to real documents rather than relying solely on its pretraining.
- Smaller models can perform better: Because the knowledge can be retrieved, the model doesn’t need to memorize everything.
- Domain adaptation: You can add specialized knowledge (e.g., company manuals, legal docs) without retraining the LLM.
- Reduced hallucinations: More grounded responses since they’re based on actual sources.
- RAG (Retrieval Augmented Generation)
1. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2020)
- Summary : RAG literally (1) retrieves the top-k documents for a given query, (2) augments the latent vector by concatenating the original input x with the retrieved passage z, and (3) generates the final output.
- Abstract
- Background. LLMs have been shown to store factual knowledge in their parameters, and achieve SOTA results when fine-tuned on down-stream NLP tasks.
- Problem Def. However, their ability to access and precisely manipulate knowledge is still limited, and hence on knowledge-intensive tasks, their performance lags behind task-specific architectures.
- Contrib. We explore a general-purpose fine-tuning recipe for RAG ? models which combine pre-trained parametric and non-parametric memory for language generation.
- Method : We explore RAG models, which use the input sequence $x$ to retrieve text documents $z$ and use them as additional context when generating the target sequence $y$.
- Retrieval (DPR) : returns top-K distributions over text passages given a query $x$
- To train the retriever and generator end-to-end, we treat the retrieved document as a latent variable.
- Generator $p_\theta(y_i | x, z, y_{1:i-1})$ : generates a current token based on a context of the previous tokens $y_{1:i-1}$ , the original input $x$ and a retrived passage $z$
- could be modelled using any encoder-decoder.
- To combine the input $x$ with the retrieved content $z$ when generating from BART, we simply concatenate them.
- Retrieval (DPR) : returns top-K distributions over text passages given a query $x$

RAG overview
2. RAPTOR: Recursive Abstractive Processing for Tree Organized Retrieval
- Abstract
- background. Retrieval-augmented language models can better adapt to changes in world state incorporate long-tail knowledge.
- Problem Def. However, most existing methods retrieve only short contiguous chunks from a retrieval corpus, limiting holistic undestanding of the overall document context.
- Contrib. We introduce the novel approach of recursively embedding, clustering, and summarizing chunks of text, constructing a tree with differing levels of summarization from the bottom up
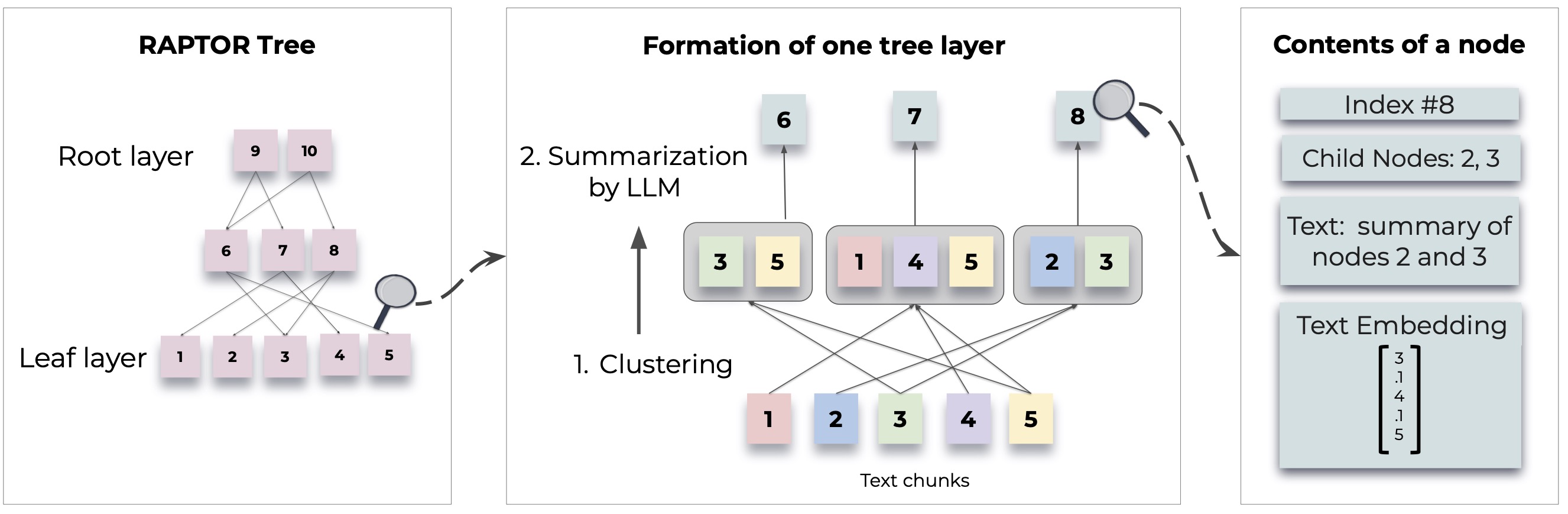
- Method : design an indexing and retrieval system that uses a tree structure - RAPTOR
- Indexing : Recursive Abstractive Processing (Embedding, Clustering and Summarization)
- Preparation : Segmenting the retrieval corpus into short, contiguous texts of length 100, similar to traditional retrieval augmentation techniques.
- Embedding : These texts are then embedded using SBERT,
- Clustering : clusters chunks of text, organizaing text segments into cohesice groups.
- Summarization : generates text summaries of those clusters with GPT3.5, and then repeats, generating a tree from the bottom up.
- Retrieval (Querying) : Collapsed tree method, offering unique ways of traversing the multi-layered RAPTOR tree to retrieve relevant information
- First, collapse the entire RAPTOR tree into a single layer.
- Next, calculate the cosine similarity between the query embedding and the embeddings of all nodes present in the collapsed set.
- Pick the top-k nodes that have the highest cosine similarity scores with the query.
- Finally, add retrieved context with query and put it into LLM
- Indexing : Recursive Abstractive Processing (Embedding, Clustering and Summarization)
RAPTOR overview