
Summary
-
Pretraining Tasks Overview
-
Masked LM : simply mask some of the input tokens at random and then predict those masked tokens
-
Next Sentence Prediction: train a model that understands sentence relationships, by a binarized next sentence prediction task.
-
1. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding (Google, 2018)
-
Introduction : introduce a new language representation model called BERT, that is designed to pretrain deep bi-directional representations from unlabeled text by jointly conditioning on both left and right context in all layers.
-
Method:
-
Input Representation = Token Embeddings + Segment Embeddings + Position Embeddings
-
Token Embeddings : [CLS] token aggregate sequence representation for classification task and [SEP] token simply diffenciate the sentences
-
Segment Embeddings : details in figure2
-
Positional Embeddings : details in transformer (Attention is all you need)
-
-
Architecture : BERT’s model architecture is a multi-layer bidirectional Transformer encoder (Only encoder part)
-
Pretrain : pre-train BERT using two unsupervised tasks
-
Task #1 Masked LM : simply mask some percentage(15%) of the input tokens at random and then predict those masked tokens
-
Task #2 Next Sentence Prediction : train a model that understands sentence relationships, by a binarized next sentence prediction task.
-
-
Finetune : For each sub-task, simply plug in the task-specific inputs and outputs into BERT and fine-tune all the parameters end-to-end
-
-
Conclusion : generalizing these findings (unsupervised pre-training can improve down-stream NLP tasks) to deep bidirectional architectures, allowing the same pre-trained model to successfully tackle a broad set of NLP tasks.
2. GPT-1: Improving Language Understanding by Generative Pre-training (OpenAI, 2018)
-
Introduction
- Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering, semantic similarity assessment, and document classification.
- Although large unlabeled text corpora are abundant, labeled data for learning these specific tasks is scarce
- We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task
- 117M params trained with BookCorpus (7K book text)
-
Method
- Unsupervised pretraining : multi-layer transformer decoder
- use a standard language modeling objective to maximize the following likelihood:
- $L_1(U) =log P(u_i|u_{i?k} ,…,u_{i?1}; ?)$
- use a standard language modeling objective to maximize the following likelihood:
- Supervised fine-tuning :
- We assume a labeled dataset $C$, where each instance consists of a sequence of input tokens, $x_1,…,x_m$, along with a label $y$.
- $L_2(C) = \Sigma_{(x,y)}log P(y|x^1,…,x^m).$
- We assume a labeled dataset $C$, where each instance consists of a sequence of input tokens, $x_1,…,x_m$, along with a label $y$.
- Unsupervised pretraining : multi-layer transformer decoder
-
Conclusion
- By pre-training on a diverse corpus with long stretches of contiguous text, our model acquires significant world knowledge and ability to process long-range dependencies which are then successfully transferred to solving discriminative tasks such as question answering, semantic similarity assessment, entailment determination, and text classification
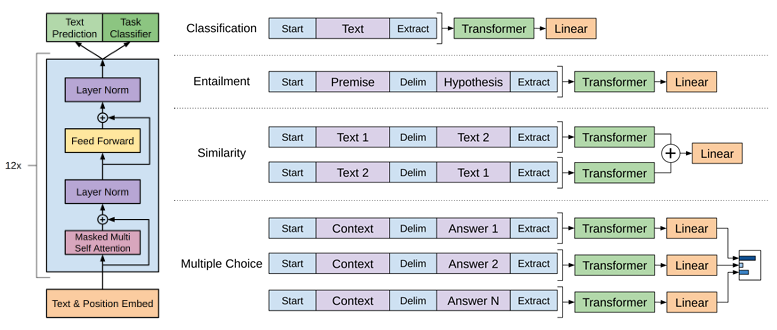
Transformer architecture and training objectives
3. GPT-2: Language Models are unsupervised multitask learners (OpenAI, 2019)
-
Introduction :
- The authors explores the idea that large-scale language models can perform a variety of NLP tasks without explicit supervision.
- The authors build on their previous model, GPT, scaling it up significantly in size and data. (1.5 billion)
- The goal is to test whether a sufficiently large transformer trained on a broad dataset of internet text can generalize to new tasks using only task descriptions as input essentially leveraging zero-shot learning.
-
Method
-
based on a Transformer decoder architecture with 1.5 billion parameters.
-
It is trained on a diverse dataset called WebText, which consists of over 8 million documents totaling 40GB of text from the internet.
-
The training is done using a simple unsupervised objective: predicting the next word in a sequence.
- GPT-2 is evaluated in a zero-shot setting across various tasks such as translation, question answering, and summarization using prompts to guide its behavior without any fine-tuning.
-
-
Conclusion
-
Previously, pretrained LLMs required supervised fine-tuning for specific downstream tasks (GPT-1).
-
GPT-2 can perform those tasks (translation, question answering, and summarization) via context alone w/o supervised finetuning.
-
4. GPT-3: Language models are few shot learners (OpenAI, 2020)
- Introduction
- The authors investigates whether scaling up language models leads to better performance on a wide range of NLP tasks with minimal supervision.
- Building on the GPT-2 approach, GPT-3 is significantly larger 175 billion parameters and trained on an even broader dataset.
- The central idea is that sufficiently large models can perform tasks via few-shot, one-shot, or even zero-shot learning, without gradient updates or task-specific fine-tuning.
- Method
- GPT-3 uses the same autoregressive Transformer architecture as GPT-2 but massively scales up the model size and training data.
- It is trained with a next-word prediction objective on a diverse corpus totaling 570GB of filtered text.
- Evaluation is conducted by prompting the model with examples of a task (few-shot), one example (one-shot), or just a task description (zero-shot), to assess its ability to generalize without fine-tuning.
- Conclusion
- GPT-3 shows strong performance across a broad array of tasks, including translation, question answering, and arithmetic, particularly in the few-shot setting.
- The paper highlights the power of scale in language models but also notes limitations such as model bias, performance inconsistency, and high computational cost.