
Introduction
-
Tasks :
- 3D object detection : classifies the object category and estimates oriented 3D bounding boxes of physical objects from 3D sensor data.
-
Applications : By extending prediction to 3D, one can capture an object’s size, position and orientation in the world, leading to a variety of applications in robotics, self-driving vehicles, image retrieval, and augmented reality
-
Benchmarks
- KITTI (car, cyclist, pedestrian easy, mod, hard) : for autonomous driving
- ScanNet : for indoor scene understanding task
- SUN-RGBD : Scene Understanding Benchmarks
- YCB-V : 21 objects from the YCB dataset captured in 92 videos with 133,827 frames.
-
Approches
-
Approaches based on Point Clouds (LiDAR)
- Projection based methods : projects point clouds to 2D planes such as bird view, front view, etc. + RPN
- Volumetric methods : voxelization + heavy 3D CNN
- Point-net based methods : extract features from raw data
- Graph based methods : construct graphs to learn the order-invariant of point clouds
-
Approaches based on monocular/stereo images
- Approaches based on cheaper monocular or stereo imagery data have resulted in drastically lower accuracies until now.
- A key ingredient for image-based 3D object detection methods is a reliable depth estimation approach to replace LiDAR.
- Existing algorithms are largely built upon 2D object detection, imposing extra geometric constraints to create3D proposals. apply stereo-based depth estimation to obtain the true 3D coordinates of each pixel.
-
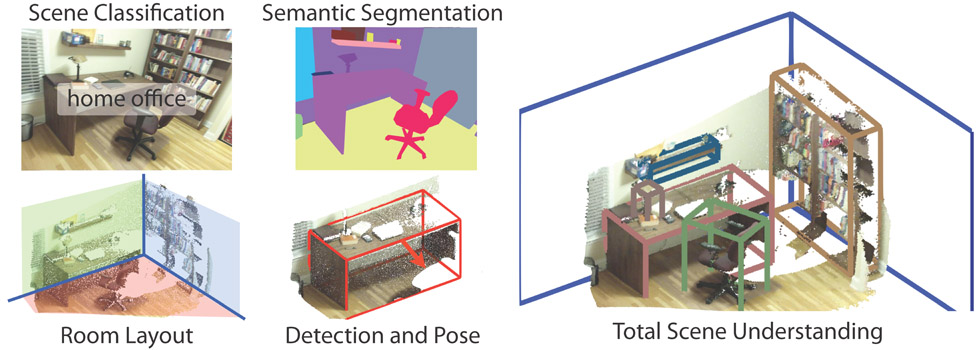
1. SUN-RGBD(2017)
-
An RGB-D benchmark suite for all major scene understanding tasks
-
Dataset is captured by four different sensors and contains 10,335 RGB-D images.
-
Densely annotated and includes 146k 2d polygons, and 64k 3D bboxes with accurate object orientations, as well as a 3D room layout and scene category for each images.
2. ScanNet(2017)
- An RGB-D Video Dataset containing 2.5M views in 1513 scenes annotated with 3D camera poses, surface reconstructions, and semantic segmentations.
3. Pseudo LiDAR(2019)
-
Introduction : Mono/stereo depth estimation based methods show worse performance than LiDAR based methods because of poor precision of image based depth estimation.
-
Contrib : convert image-based depth maps to pseudo-LiDAR representations
-
Methods :
-
convert the estimated depth map from stereo or monocular imagery into a 3D point cloud, which we refer to as pseudo-LiDAR
-
then take advantage of ex-isting LiDAR-based 3D object detection pipelines
-
4. Realtime 3D Obj Detection on Mobile Dev with Media Pipe (Google, 2020)
-
Introduction : detects objects in 2D images, and estimates their poses and sizes through a ML model, trained on a newly created 3D dataset
-
Obtaining real world 3D Training Data : using ARCore, Google’s AR Platform, integrated in most smartphones, which can provide the information of the camera pose, sparse 3D point clouds, estimated lighting, and planar surfaces.
-
AR Synthetic Data Generation : places virtual objects into scenes that have AR session data.
-
An ML Pipeline : a single-stage model to predict the pose and physical size of an object from a single RGB image
5. SVGA-Net(2020)
-
Introduction : graph based methods for point clouds data, 2020 SOTA in KITTI datasets
-
Methods : Spars Voxel Graph Attention Network
Appendix. LiDAR, ToF and Point Clouds
- Introduction : LiDAR systems send out pulses of light just outside the visible spectrum and register how long it takes each pulse to return. Once the individual readings are processed and organised, the LiDAR data becomes point cloud data. A 3D point cloud is a collection of data points analogous to the real world in three dimensions. Each point is defined by its own position and (sometimes) colour.
- Photogrammetric point clouds : have an RGB value for each point, resulting in a colourised point cloud (acqutision using digital camera rather than LiDAR, worse than LiDAR in terms of accuracy).
- Difference between LiDAR and TOF : A ToF(most android phones) is a scannerless LiDAR system, relying on a single pulse of light to map an entire space, while Apple is using scanner LiDAR, which uses multiple points of light to take these readings much more frequently and with greater accuracy.
- LiDAR & TOF in mobile : LG G8 (2019) , Galaxy Note10, S20, IPAD pro 4, iphone12 , Huawei Mate30, Sony Xperia2
Appendix. AR Applications on smartphones
-
Google AR Core Depth API : Single Camera Depth Estimation
-
IKEA Place : allows the user to directly insert furniture into a picture of the room
-
modiFace : virtual beauty counter
-
measure kit : AR Ruler
-
pixie : find lost key through the iPhone screen. (with Bluetooth hardware)
-
magic sudoku : Solve sudoku puzzles in AR
Appendix. Stereo/monocular image based depth Estimation
-
Benchmarks
- NYU Depth (Mono) : includes 1449 densely labeled pairs of aligned RGB and depth images
- KITTI Eigen Split (Mono) : part of the KITTI dataset proposed by D.Eigen et al. for monocular depth estimation task
-
BTS (monocular) : a network architecture that utilizes novel local planar guidance layers located at multiple stages in the decoding phase.
-
DORN (monocular) : combine multi-scale features with ordinal regression to predictpixel depth with remarkably low errors
-
PSMNet : applies Siamese networks for disparity estimation, followed by 3D convolutions for refinement
-
Y Wang et al. : has made these methods more efficient, enabling accurate disparity estimation to run at 30 FPS on mobile devices.
Appendix. 3D Modeling
- IKEA 3D Models : includes a lot of simple CAD models, but there’s no additional information required for detection like RGBD, point clouds, etc.
- These 3D Models can be used to estimate the 3D pose of specific objects in image ( Lim et al. ICCV2013 )