
Introduction
-
Tasks
- Object Detection : a task of finding the different objects in an image and classifying them
- Salient Object Detection : a task based on a visual attention mechanism, in which algorithms aim to explore objects or regions more attentive than the surrounding areas on the scene or RGB images.
-
Metrics:
- AP or mAP is generally used as the primary metrics metric.click here for details
-
Others
-
Non Maximum Suppression (NMS) :
-
(1) get multiple bbox for each object
-
(2) Leave the most confident bbox and remove other bboxes which has high IoU with it
-
-
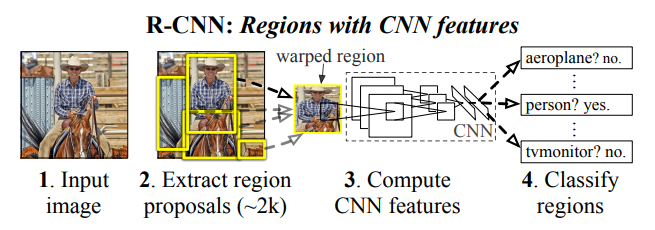
1. R-CNN (2013)
-
Introduction : An early application of CNNs to Object Detection tasks
-
Method
-
Region Proposals : Generate a set of proposals ($n=2000$) for bounding boxes using selective search algorithm.
-
Resize Regions : resize ROI patches to 224x224 for pretrained AlexNet
-
Classification : Run the images in b-boxes through a pre-trained AlexNet and SVM to see what object the image in the box is.
-
b-box regressor : Run the b-box through a linear regression model to output tighter coordinates
-
cf. Selective search looks at the images through windows of different sizes and for each window, tries to group together adjacent pixels by texture, color, or intensity to identify objects
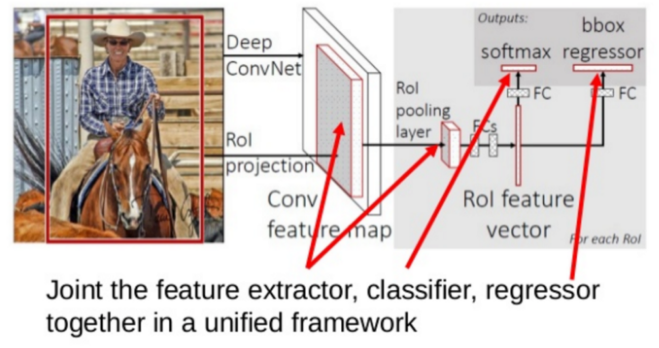
2. Fast R-CNN (2015)
-
Introduction : RCNN was quite slow because of 2000 (number of Region patches) forward passes per image (for all proposed regions). And also it need to train three different models separately (CNN, SVM, regression). Fast-RCNN tried to solve these problems.
-
Method
-
pretrained CNN : get top-conv feature map using pretrained CNN
-
Region Proposal : just get ROI coordinates from input image using selective search, and does not make image patches.
-
ROI pooling : conv-features for each proposed ROI are obtained by selecting a corresponding region from the feature map of input image instead of running CNN for every ROI patches. Then, these conv-features are pooled adaptively.
-
Classification & B-Box regressor
-
3. Faster R-CNN (2016)
-
Introduction : There was still one remaining bottleneck in the Fast R-CNN : the region proposer based on selective search.
-
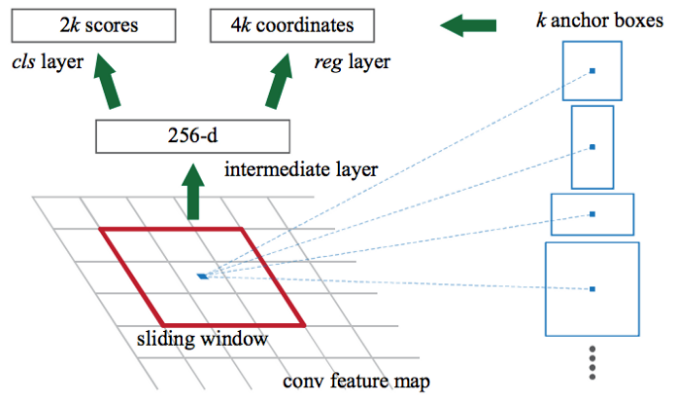
Method : adds a Fully Convolutional Network which is called Region Proposal Network between the top-conv feature map and ROI pooling. The RPN slides a window over the top-conv features. At each window location, the network ouputs a score and a bbox per anchor.
-
Pretrained CNN : Run the image through a CNN to get a (top-conv) feature-map. (returns 14x14x512)
-
Region Proposal Network: slide a small conv-net over the extracted feature-map which maps the input window to lower-dimensional feature (256-dim). Then this lower-dim feature is fed into two sibling FC layers, one for box-classification and the other for box-regression.
-
2.1 Classifier : returns 14x14x9x2 (9 for anchor and 2 for object/background)
-
2.2 Box Regressor : returns 14x14x9x4 (9 for anchor and 4 for dx, dy, w, h)
-
-
ROI Pooling & Classification : same as faster RCNN
-
4. Mask R-CNN (2017)
-
Introduction : to detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance.
-
Method : just add a third branch that outputs the object mask.
-
Feature Extraction is same as Faster RCNN
-
RPN is same as Faster RCNN
-
The 3rd tails outputs (class + box offset + a binary mask) for each ROI in parallel.
- 3.1 : Class labels are collapsed into a short output vectors by FC layers, same as Faster RCNN
- 3.2 : Box offset is collapsed into a short output vectors by FV layers, same as Faster faster_RCNN
- 3.3 : $m \times m $ masks are predicted for each ROI using an FCN
-
ROI Align : If we use ROI pool at the above process, there would be small difference between the real ROI and extracted feature map. It does not matter in classification task, but does in segmentation. To address this problem, authors proposed ROI Align.

-
5. SpineNet (2020)
-
Introduction : In past few years, most networks follow the design that encodes input image into intermediate features with monotonically decreased resolutions. Most improvements of network architecture design are in adding network depth and connections within features resolution group.
-
Authors demonstrate that SpineNet can also be used as backbone model in Mask-RCNN Detector and improve both box detection and instance segmentation