
Introduction
-
Tasks:
-
Image Classification : The task of classifying an image according to its visual content.
-
Image Representation : focus on the way to encode visual contents into vectors (embedding, encoding)
-
1. AlexNet (2012)
- Introduction : CNNs have been prohibitively expensive to apply in large scale to high resolution images.
- Method : Training on Multiple GPUs
def AlexNet(x):
out = MP(relu(conv11x11(x)))
out = MP(relu(conv5x5(out)))
out = relu(conv3x3(out))
out = relu(conv3x3(out))
out = MP(relu(conv3x3(out)))
out = FC(relu(FC(relu(FC(out)))))
return out
2. VGG Net (2014)
- Introduction : come up with significantly more accurate ConvNet
- Method : deeper ConvNet
def VGG16(x):
out = MP(conv3x3(conv3x3(x)))
out = MP(conv3x3(conv3x3(out)))
for i in range(3):
out = MP(conv3x3(conv3x3(conv3x3(out))))
out = softmax(FC(FC(FC(out))))
return out
3. GoogleNet (2015)
- Introduction : efficient deeper networks (with fewer params than AlexNet)
- Method : inception module(NIN, Bottleneck)
def inception_block(x):
branch_1x1 = conv1x1(x)
branch_3x3 = conv3x3(conv1x1(x))
branch_5x5 = conv5x5(conv1x1(x))
branch_pool = conv1x1(MP3x3(x,same))
out = concat([branch_1x1,branch_3x3,branch_5x5,branch_pool])
return out
4. ResNet (Microsoft, 2015)
- Introduction : to solve the degradation problem caused by deeper layer.
- Method : Residual Block with shortcut(skip) connection defined as :
$$ \mathbf{x}_{l+1} = \mathbf{x}_l + F(\mathbf{x}_l,{W_i}) $$
def residual_block(x):
out = relu(bn1(conv3x3(x)))
out = relu(bn2(conv3x3(out)) + x)
return out
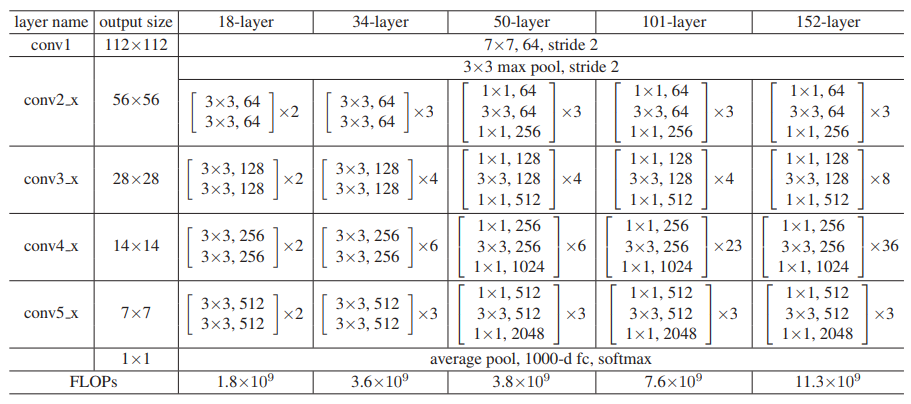
5. DenseNet (2016)
- Introduction : information about the input or gradient can vanish and wash out as CNNs become deep
- Method : Dense Connectivity (not sum, just concat)
- Result : 77.85% of top-1 accuracy in ImageNet
$$ x_l = H_l([x_0, x_1, … , x_{l-1} ]) $$
$[x_0, x_1, … , x_{l-1}]$ means concatenation of the features-maps produced in previous layers.
def dense_block(x):
out = conv1x1(relu(bn1(x))) # Bottleneck for comput. efficiency
out = conv3x3(relu(bn2(out)))
out = concat([x, out])
return out
6. ResNeXt (2016)
- Introduction : present a improved architecture that adopts ResNets strategy of repeating layers.
- Method : split-transform-merge strategy (cardinality)
- Result : 80.9% of top-1 accuracy in ImageNet with 83.6M params
$$ \mathbf{x}_{l+1} = \mathbf{x}l + \sum{i=1}^{cardin} F_i(\mathbf{x}_l) $$
def residual_block(x):
out = relu(bn1(conv3x3(x, groups=cardinality)))
out = relu(bn2(conv3x3(out, groups=cardinality)) + x)
return out
7. ShuffleNet(2017)
-
Introduction : extremely computation-efficient CNN architecture named ShuffleNet, designed specially for mobile devices with very limited computing power.
-
Methods : utilizes two new operations, pointwise group convolution and channel shuffle
-
divide the channels in each group into several subgroups
-
feed each group in the next layer with difference subgroup
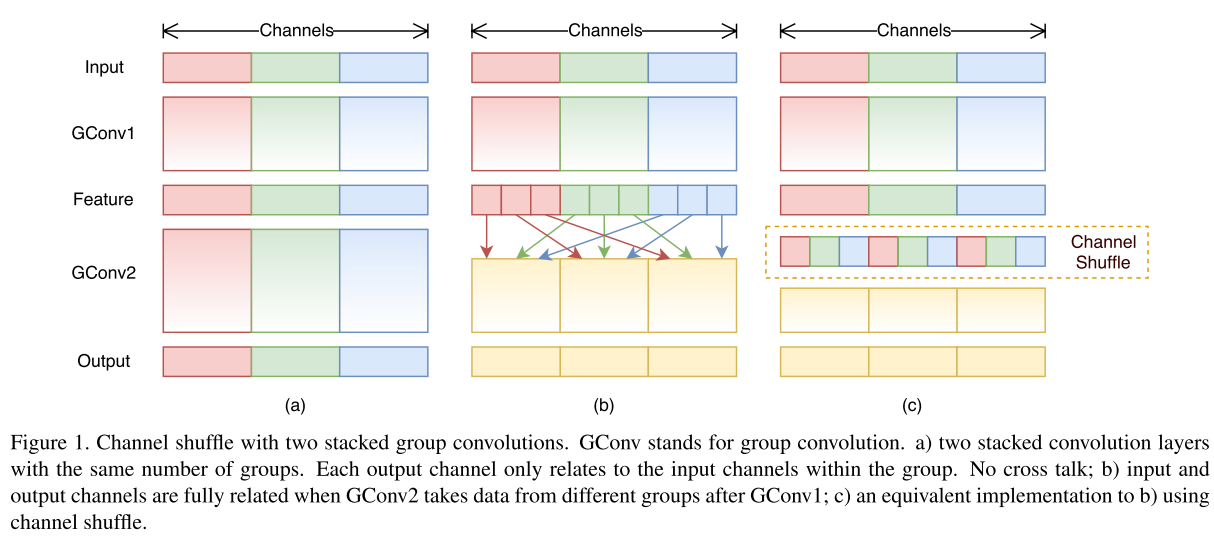
-
8. FixResNeXt (2019)
- Introduction : Existing augmentations induce a significant discrepancy between the size of the objects seen by the classifier at train and test time.
- Method : Simple strategy to optimize the classifier performance, that employs different train and test resolution : in face, a lower train resolution improves the classification at test time.
- Result : 86.4% of top-1 accuracy in ImageNet with 83.6M params

9. ViT : An Image is Worth 16x16 Words (2020, GoogRes)
-
Introduction :
- Transformer architecture has become the de-facto standard for natural language processing tasks
- In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place
- We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks.
-
Methods : applying a standard Transformer directly to images
-
Patch Embedding $x_i$ : extracts N non-overlapping image patches, performs a linear projection ($E$, is equivalent to a 2D conv) and then rasterises them into 1D token.
-
learnable embedding $z_{cls}$ : an optional learned clasification token (Similar to BERT’s [cls]) is prepended to the sequene of embedded patches
-
learnable position embedding $p$ : added to the tokens to retain positional information,
=> When you have no idea about how to hand-craft positional encoding for your data
=> Let the transformer figure out for itself what it needs as positional embeddings
=> simply train the vectors in table of figure at “NLP3 > Transformer > Binarized Indexing”
$$ \mathbf{z} = [z_{cls}, E_{x_1}, E_{x_1}, …, E_{x_1}] + \mathbf{p}
$$ -
-
Result:
- When trained on mid-sized datasets such as ImageNet(1.3M) without strong regularization, these models yield modest accuracies of a few percentage points below ResNets of comparable size
- However, the picture changes if the models are trained on larger datasets (JFT-300M, Figure3)
10. VirTex : Learning Visual Representations from Textual Annotations
- introduction : revisit supervised pretraining, and seek data-efficient alternatives to classification-based pretraining.
- (1) Semantic density : Captions provide a semantically denser learning signal than unsupervised contrastive methods and supervised classification.
- (2) simplified data collection : natural language descriptions do not require an explicit ontology and can easily be written by non-expert workers,
- VirTex : a pretraining approach using semantically dense captions to learn visual representations
- (1) jointly train a ConvNet and Transformer from scratch to generate natural language captions for images
- Visual Backbone : a convolutional network which computes visual features of image
- Textual Head : receives features from thevisual backbone and predicts captions for images
- (2) transfer the learned features to downstream visual recognition tasks
- (1) jointly train a ConvNet and Transformer from scratch to generate natural language captions for images
- Result
- show that natural language can provide supervision for learning transferable visual representations with better data-efficiency than other approaches.
- VirTex matches or exceeds the performance of existing methods for supervised or unsupervised pre-training on ImageNet, despite using up to 10×fewer images