
1.0 Introduction
- Data-intensive (vs compute-intensive) : raw CPU power is out of interest, bigger problems are usually the amount of data, the complexity of data, and the speed at which it is changing
- Database : store data so that they, or another application, can find it again later
- Caches : Remember the result of an expensive operation, to speed up reads
- Search Indexes : Allow users to search data by keyword or filter it in various ways
- Stream Processing : Send a message to another process, to be handled asynchronously
- Batch Processing: Periodically crunch a large amount of accumulated data
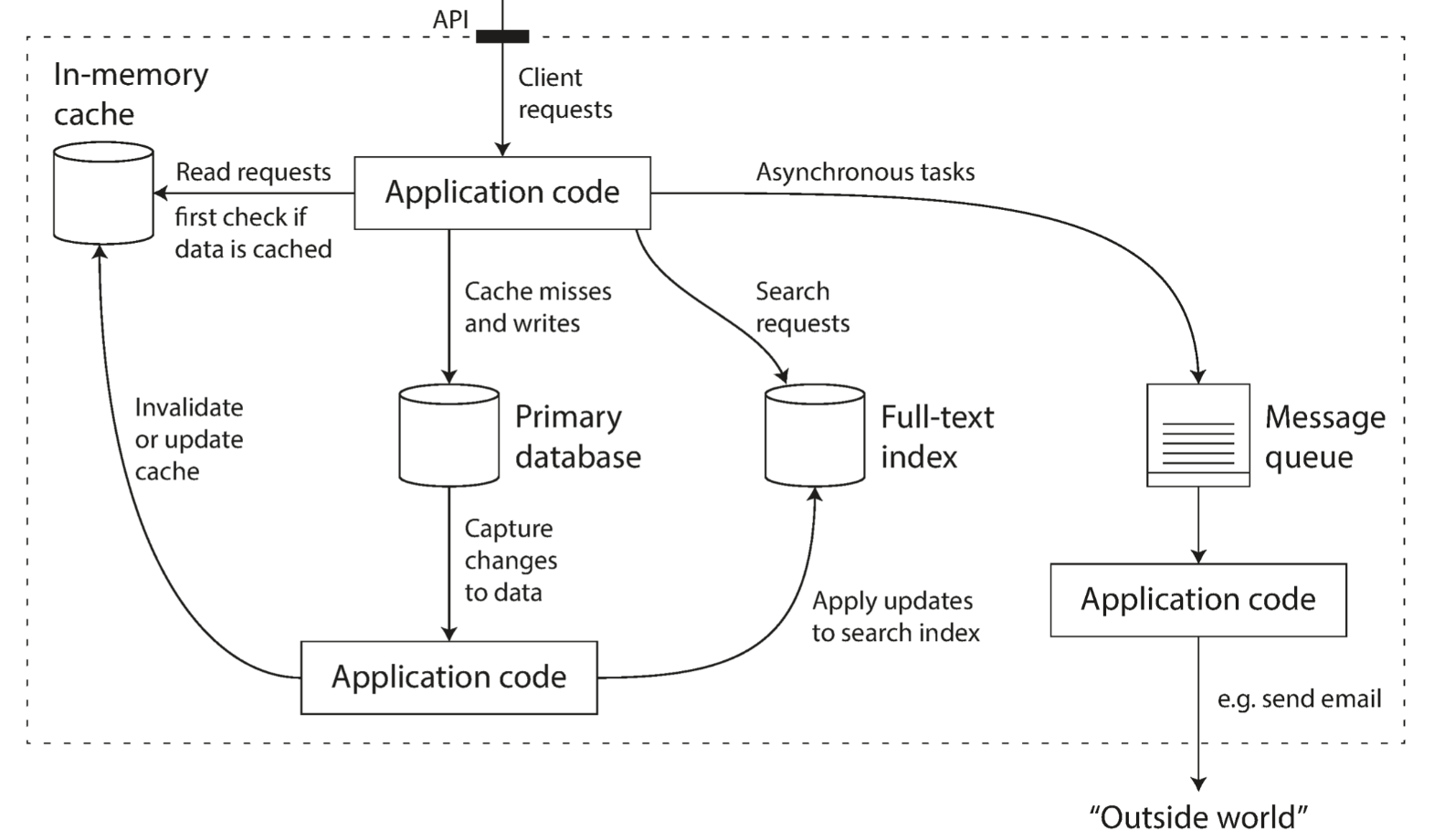
1.1 Reliability
- Reliability : The system should continue to work correctly (performing the correct function at the desired level of performance) even in the face of adversity (hardware or software faults, and even human error)
- Hardware Faults : 하드디스크 고장, 램 결함, 정전, 케이블 분리 등과 같은 하드웨어 결함, 대체로 독립적
- Software Errors : 하드웨어와 달리 다수의 궝요서에 동시장애가 발생할 수 있음
- Human Errors : 시스템을 설계하고 구축, 운영하는 과정에서 실수발생
1.2 Scalability
- Scalability : As the system grows, there should be resasonable ways of dealing with that growh
- Describing Load : 부하기술하기 => 시스템의 현재 부하를 간결하게 기술할 수 있어야 부하 성장을 논의할 수 있음
- Describing Performance
- response time : 응답시간을 활용한 현재 서버의 성능 기술하기 => 대개 산술 평균을 많이 이용하지만 이보다는 백분위를 이용하는게 좋다 ( p50-중앙값, P999-응답시간이 가장 느린 요청 위주로 - 가장 많은 데이터를 갖고 있는 VIP일 확률이 높다 )
- Approaches for Coping with Load - scaling up (vertical scaling): 사양이 좋은 장비로 업그레이드 - scaling out (horizontal scaling): 사양이 낮은 다수 장비로 부하를 분산
1.3 Maintainability
- Maintainability : both maintaining current behavior and adapting the system to new use cases => should be able to work on it productively
- Operability ; 운영, 유지보수를 편리하게
- Simplicity ; 프로젝트 전반의 복잡도 관리
- Evolvability ; 요구사항에 맞춰 시스템 변경을 용이하게
1.4 Summary
- In this chapter, we have explored some fundamental ways of thinking about data intensive applications.
- An Application has to meet various requirements in order to be useful. (Functional and nonfunction requiremnets)
- Reliability means making systems work correctly, even when faults occur
- Scalability means having strategis for keeping performance good, even when load increases
- Maintainability has many facets, but in essence it’s about making life better for the engineering and operations terms who need to work with the system.
1.5 Appendix
-
DB read/write 비율 : 1.2절의 Describing Load 에서 response time 과 함께 DB의 read/write 도 중요한 load param
-
DB마다 조금씩 다르지만, read/write를 담당하는 인스턴스가 다르며
- Write 는 보통 primary (leader/master) 가 담당
- Read 는 secondary (follower/slave) 가 담당
-
Write-Heavy 한 경우 primary가 여러개가 되도록 설계
- sharding을 적용하여 primary-secondary가 여러쌍 나오도록
- sharding이란 => 같은 테이블 스키마를 가진 데이터를 다수의 DB로 분산하여 저장 (DB 를 horizontal로 자름)
- e.g., shard1 : primary-secondary (id 1~100까지 저장) / shard2 : primary-secondary (id 101~200까지 저장)
-
Read-Heavy 한 경우 primary를 그대로 두고 많은 secondary로 replication
- sharding 없이 primary-N member secondary
- N member로 분산시켜 접속
-
Read/Write 가 heavy 하지 않터라도 replication/sharding
- Read-heavy 관계없이 high availability 를 제공하기 위해 replication을 적용하는게 일반적
- Write-heavy 하지 않아도 초기 데이터가 너무 많은경우 read performance 향상을 위해 sharding 가능
-
-
추천 서비스 사례
- 추천 서비스의 경우 read-heavy, write는 우리가 조절 가능
- Redis 속도가 매우 빨라서 master-slave 3pair , 총 6대로 4000qps를 여유있게 처리
- write는 ras/neo4j 가 병목이라 이쪽에 맞추고 있음.
- Redis - Telegraf (InfluxData사) - InfluxDB : Redis 에 붙여주면 telegraf 가 필요한 load param을 timeseries로 influxDB에 넣어줌